Simple Chain of events that brought down Slack
A routine software update that should have taken minutes accidentally deleted Slack's entire cache, triggering a chain reaction that brought down one of the world's most-used workplace tools.
On 22 Feb 2022, Slack stopped working. This happened not because of any human error but because of an extremely unlikely yet simple chain of events. Caching was at the center of this outage.
Caching Architecture at Slack
On the surface, caching is a fairly straightforward pattern we use in all of our backend services. But before jumping into the sequence of events that caused the outage, we need to understand the caching architecture of Slack’s backend APIs, utilizing cache extensively.
MySQL with Vitess for storage
Several MySQL servers were used for userdata. But these MySQL servers were not standalone instances. These were managed by a MySQL orchestrator called VitessFirst developed at Youtube, Vitess is now used by Slack, Shopify, Flipkart to name a few. Vitess distributes large MySQL tables between several MySQL servers. For example, Vitess can distribute rows of a single 10 Terabyte table across 10 MySQL instances.
Memcached for caching
At Slack, several Memcached servers are used for caching. Memcached is an in-memory key-value store. If a new server starts, then it will never recover the old data, which is fine if Memcached is used for caching large amounts of data.
Consult for the service registry
Slack also used Consul as a service registry. Think of Consul as a phonebook that updates itself in real time — when a server goes offline, its number is removed. When it comes back, it's added again. Consul does this by running a process called the Consul Agent on all memcache servers. Consul agent sends heartbeats to the Consul Server to notify that the Memcached servers are alive. If a memcached server goes down, then the Consul agent will stop sending heartbeats. The Consul server will immediately flag the Memcached server as down.
McRib for memache cluster recovery
Then there is a final component at Slack called MCRib. This is a proprietary software component at Slack that ensures the availability of memcached clusters. Every time a memcached server goes down, the Consul server notifies McRib that a Memcached server might be down and McRib creates a new Memcached server.
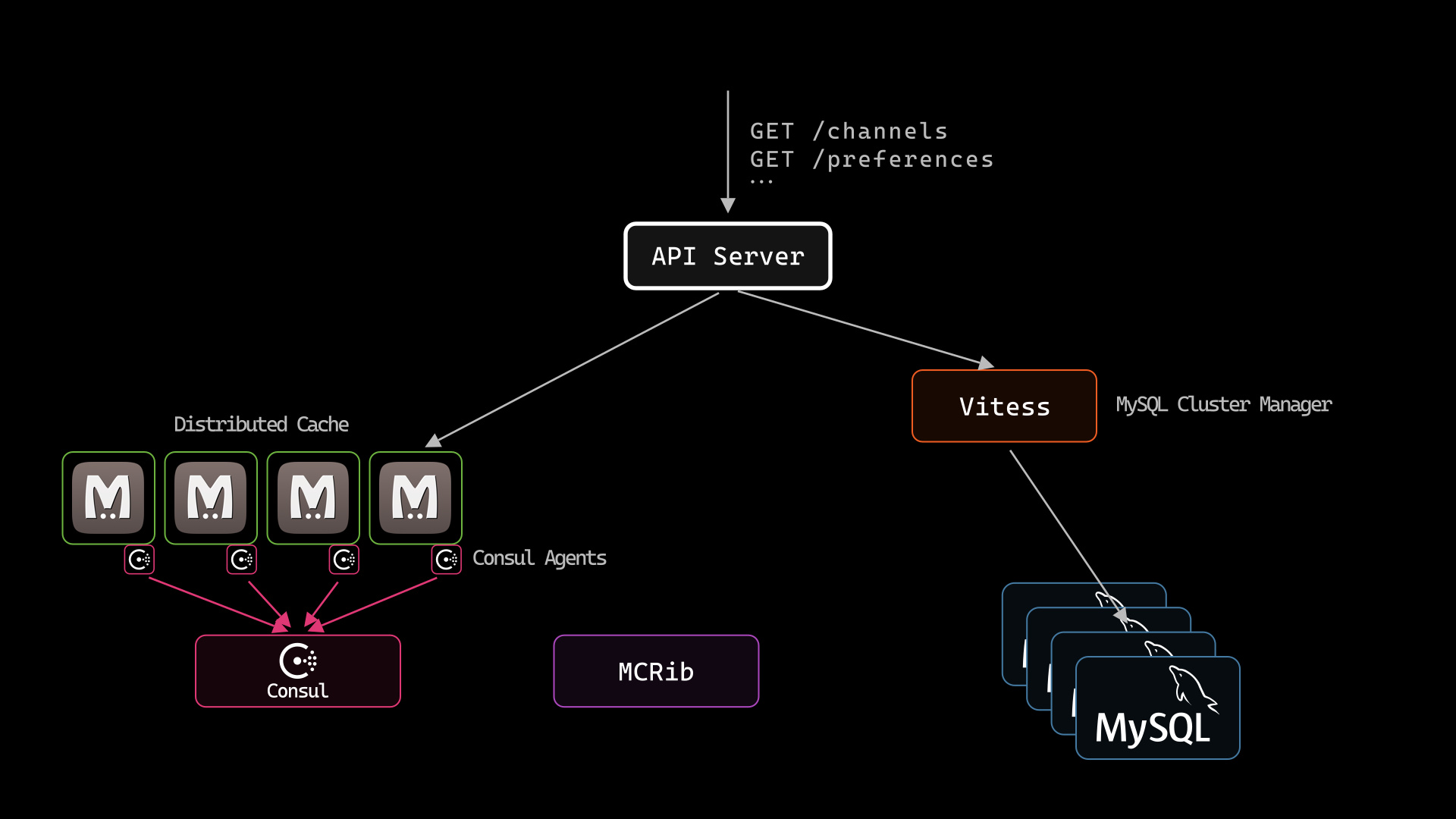
So the API workflow looks like this.
- For every API hit, Slack's API queries Memcached.
- When there is no value in Memcached, the MySQL cluster is queried for the data.
- Since the user data can be distributed across several MySQL servers, Vitess might send SQL queries to 100’s of MySQL servers. MySQL queries can be extremely costly when Vitess has to send a single query to 100’s of MySQL servers. But generally, the miss rate in memcache is low. So MySQL instances receive less traffic, which they can manage.
- Remember this point: If MySQL query’s response is slow, then the API server triggers an automatic retry after a timeout. It retries the MySQL query a few times.
What led to the outages?
Consult Agent update
On February 22nd, Slack's devops team was performing a routine upgrade of the Consul agent. Consul agent is a small process that runs as a sidecar on every server in their fleet, including their memcache servers. Its job is simple: register the server as healthy and available. When the agent shuts down, even briefly, it deregisters that server from the catalog.
Slack had a component called Mcrib that watched this catalog. The moment a memcache node disappeared, Mcrib assumed it was dead and replaced it with a fresh, empty spare. When the original node came back up, Mcrib flushed it before putting it back into rotation — to avoid serving stale data. So every single Consul agent restart caused two cold cache nodes instead of one.
The team rolled this out in 25% batches — the standard, safe way to deploy infrastructure changes. The first batch went fine. The second batch went fine. But by the third batch, at peak traffic, enough cache had been silently evicted that the system crossed a tipping point. MySQL query volume spiked many times over, and the cluster buckled.
Side effects of the Consul Agent upgrade
The engineers thought they were doing a Consul Agent upgrade. Suddenly, the MySQL cluster went down. Slack became completely unavailable, and there was no quick fix for this outage. The cached data, which was lost, cannot be recovered. To recover from this situation, we first need to understand the root cause.
Firstly, a cache lookup is O(1) operation, whereas a SQL query on N instances of MySQL is an O(N) operation (where N is the number of instances of MySQL). According to some estimates, Slack has several thousand MySQL servers. So a single SQL query can be several thousand times more expensive than a memcached query.
Secondly, if the traffic to MySQL increases, its response time goes up. If you remember, Slack’s API service had a retry logic. Since MySQL is getting slow, a cache miss on one key cascades into several SQL queries. This further triggers an increase in the number of MySQL queries. There is a compounding effect at play here, which comes in like a tsunami of requests to the MySQL cluster. Such systems are called metastable systems. These systems seem stable till one small change causes a chain reaction and a sudden failure.
Interestingly, the unfortunate meltdown at the Chornobyl reactor was also a metastable complex system. Every individual decision at Chornobyl was locally correct — the operators followed procedure, the engineers ran the test as designed. But the system's physics made catastrophic failure inevitable once a certain threshold was crossed.
What can we learn from this?
Importance of load-testing
As much as possible, we should load-test such chaotic scenarios in advance. In this case, the key test was simple: load test with an empty memcache.
Importance of circuit breakers and throttlers in microservice environment
But no amount of research and experimentation can ever discover all the unknowns. We need to build circuit breakers and throttlers in front of all the key systems. And we need to use these circuit breakers if severe outages occur. It feels extremely counterintuitive to forcibly stop accepting requests when the system is already down and not responding. But in cases like this, there is no other way to protect critical systems like MySQL cluster, providing it enough time to recover from the downward spiral was the only possible action that could be taken immediately.
At Nurburg.dev, we have created an experiment that recreates exactly this scenario. We would love for you to visit our platform and explore the experiment. See if you can identify why the system is metastable and fix it to avoid the positive feedback loop.