Transaction ID Wraparound in Postgres: an outage to remember
How Sentry's PostgreSQL primary stopped accepting writes in 2015 due to XID wraparound — a knowable failure that many production systems are still vulnerable to.
Databases have their quirks. Some are well-documented, some are discovered the hard way, and some are both — known issues that slip through the cracks when teams are heads-down shipping product.
PostgreSQL has a documented limitation with transaction IDs. It's been in the manual for years, the fix is routine maintenance, and the warning signs are observable. And yet, in January 2015, Sentry ran headfirst into it, bringing their core infrastructure to a halt. What makes this incident worth studying isn't that it was unpredictable. It's the opposite. The XID wraparound problem is knowable. Yet the operational gap like this exists in many production systems.
This post walks through what happened, why it happened, and what you can do to make sure it doesn't happen to you.
XID and MVCC architecture
PostgreSQL implements MVCC — Multi-Version Concurrency Control — to satisfy ACID guarantees without locking reads against writes. The core idea is simple: instead of overwriting a row on update, PostgreSQL writes a new version of it. Every transaction gets a transaction ID — an XID — and every row version is stamped with the XID that created it and the XID that obsoleted it. When a query runs, it sees only the row versions that were committed before its own XID, giving it a consistent snapshot of the database without blocking other writers.
XIDs are 32-bit unsigned integers. This was a practical choice — 4 bytes per row is cheap, and back when PostgreSQL was designed, 2³² transactions felt like enough headroom. At roughly 4 billion transactions, the counter will overflow. To prevent this, when XIDs are about to reach the upper limit, PostgreSQL stops accepting write operations.
Old row versions don't disappear automatically. Vacuuming is the process that reclaims them. Vacuuming scans the tables, identifying rows no longer visible to any active transaction, and marking that space reusable. Autovacuum does this in the background, but on large tables with heavy write loads, it can fall behind.
PostgreSQL recommends tuning a few parameters for such tables:
- How long autovacuum pauses between bursts of work to avoid overloading the system (
autovacuum_vacuum_cost_delaydelay between bursts of vacuuming activity). - How much of a table needs to have changed before a vacuum is triggered at all (
autovacuum_vacuum_scale_factorfraction of table that must be dead tuples for vacuuming to start).
The defaults for both are too conservative for a large table. Making these more aggressive ensures dead rows are cleaned up before they accumulate into a problem. PostgreSQL also exposes a view that shows statistics on how much bloat dead rows are causing in different tables (pg_stat_user_tablesvacuum and dead tuple statistics per table). These statistics are worth monitoring routinely on write-heavy workloads.
Sentry’s backend architecture
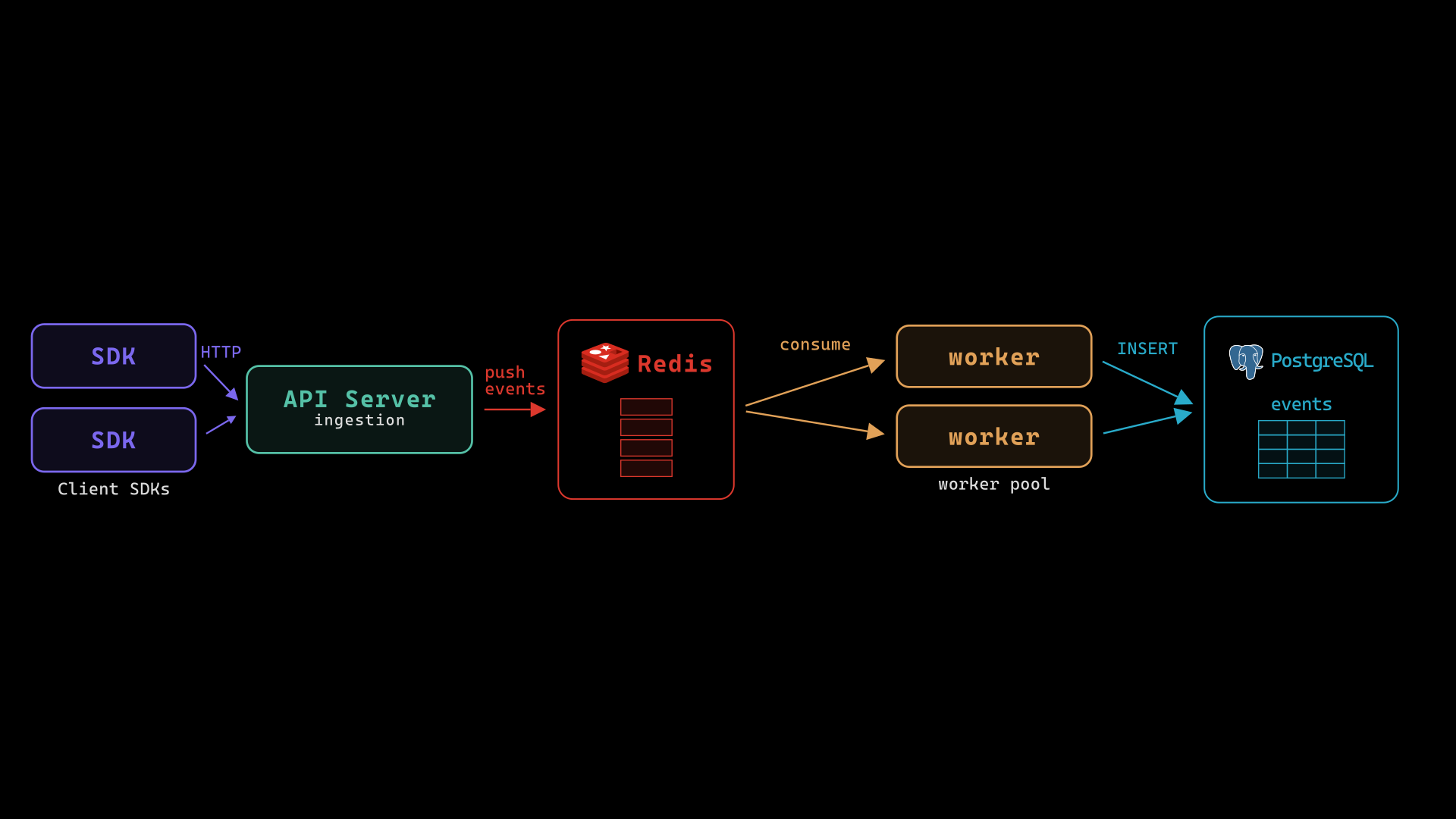
At the time of the incident, Sentry's ingestion pipeline was straightforward. Client SDKs captured exceptions and sent them as events to Sentry's backend. These events were pushed to a Redis queue, where a pool of workers consumed them and ingested records into PostgreSQL — primarily into a central events table.
This is a common and reasonable architecture for this class of problem. Redis absorbs the spiky, unpredictable nature of error ingestion — a deployment gone wrong can flood the queue in seconds — and the workers drain it at a pace the database can handle. PostgreSQL sits at the persistence layer, the source of truth for everything Sentry surfaces to users.
The day the counter ran out
In July 2015, Sentry's PostgreSQL primary stopped accepting writes. The XID counter had reached its limit. So the database entered a protective freeze — a deliberate safeguard. If PostgreSQL didn't do this, XID overflow would lead to data corruption.
In Sentry’s backend architecture, this situation was manageable. Read replicas were still serving traffic, so the product remained partially functional for users querying existing data. More importantly, the ingestion pipeline was still alive for the time being. Events were arriving from client SDKs, getting pushed onto Redis, and sitting there waiting for workers to drain them into PostgreSQL. Redis streaming was buying time.
Parallely, autovacuum was already running, working through the frozen tables to reclaim XIDs and bring the database back. But the issue was that no one was sure how long autovacuuming would take. Vacuum progress on large tables is difficult to estimate.
Meanwhile, Redis was filling up. Workers had nowhere to drain events — PostgreSQL wasn't accepting writes — so Redis’s memory usage grew. At some point, holding everything in memory was not possible. Sentry made the difficult call to start dropping events from Redis. For a company selling error monitoring, this was the worst possible failure mode.
To accelerate recovery, the team took an aggressive approach: truncation of large tables. Rather than waiting for autovacuum to crawl through billions of dead row versions, truncating tables resets XID state immediately. It is a destructive historical event; data was lost in the process, but it was the fastest path to getting the database accepting writes again and stopping the bleeding on Redis.
Lessons learned
Sentry's postmortem was candid about what went wrong operationally. Before the incident, autovacuum was configured to wait too long before triggering a freeze cycle (autovacuum_freeze_max_agemax XID age before forced freeze), and only the default 3 workers were available to handle maintenance across all tables (autovacuum_max_workersnumber of concurrent autovacuum processes). On top of that, vacuuming was deliberately slowed down to reduce system load — a tradeoff that looked reasonable until it wasn't (autovacuum_vacuum_cost_delaydelay between bursts of vacuuming activity).
After the incident, Sentry moved to a more aggressive posture. More workers were assigned to vacuum concurrently, the idle time between vacuum runs was tightened significantly (autovacuum_naptimehow often autovacuum wakes to check tables), and the artificial throttle on vacuum speed was removed entirely. They also provisioned new hardware with substantially more memory dedicated to maintenance operations (maintenance_work_memmemory available to vacuum operations).
The underlying lesson is straightforward: on write-heavy systems, treating autovacuum as a low-priority background process is a risk that accumulates silently. By the time it surfaces, the options are limited, and none of them is clean.
Beyond the Incident: A Note on Queue Design
One architectural takeaway from Sentry's incident that doesn't get discussed enough is the choice of Redis as the primary buffer between ingestion and the database. Redis is fast and operationally simple, but its capacity is bounded by available RAM. Under sustained backpressure — exactly the situation Sentry faced — it runs out of room quickly, and the only options left are to block or to drop.
Kafka, RabbitMQ, and similar message brokers are designed for this scenario. They spill to disk, handle backpressure gracefully, and can absorb hours of write pressure without data loss. The tradeoff is operational complexity, but for systems where the queue sits in the critical path, that complexity is worth it.
This isn't theoretical. At a large e-commerce company I worked with, the order placement service was wired to write to RabbitMQ rather than directly to MySQL. On the morning of their largest flash sale of the year, MySQL went down. Order reads stopped. But order placement kept working — RabbitMQ absorbed the backlog without complaint. Some overbooking happened, and the team spent the days after the sale procuring additional inventory to fulfil the extra orders. Not ideal, but recoverable. If the queue had been Redis-backed and memory-bound, the placement service would have likely stopped accepting orders entirely during their highest-traffic window of the year.
The broader lesson here is that we should design to minimise points of failure in the critical path. Read failure is bad. But in most cases, write operations failing is worse. A durable queue between your application and your database ensures that even when persistence has a bad day, you are not discarding your most important data.
Hands-on challenge
The best way to internalise this incident is to recreate it. We've built a challenge around exactly this scenario — a simplified event ingestion pipeline with chaos injected at the persistence layer. Your job is to ensure no acknowledged event is ever lost.
