Distributed Transactions with the SAGA Pattern
Distributed systems can't use database transactions to span multiple services. The SAGA pattern is how you get consistency anyway — but it comes with constraints most teams underestimate.
Most backend engineers learn transactions in the context of a single database: begin, do some work, commit or rollback. The database handles isolation, atomicity, and durability. You don't have to think much about partial failure — either everything lands or nothing does.
This approach is not possible in a few cases.
- When your data lives in more than one place — for example, a system that books a multi-leg airline ticket where each leg is operated by a different airline.
- When your data is so large that 1 SQL database wont be able to store all the data on 1 server In some cases sharding SQL database is not scalable due to nature of the data stored..
The problem with distributed state changes
A customer in Allahabad needs to reach Mangalore. There is no direct flight — the itinerary connects through Mumbai. The first leg is on IndiGo, the second on Air India. To confirm the booking, three things must happen in order:

Each operation lives in a different system. There is no single transaction that spans all three.
If step 1 succeeds but step 2 fails, IndiGo is holding a seat for a passenger with no onward connection. If both seats are confirmed but payment fails at step 3, two airlines are holding inventory for a booking that will never be paid. Partial success leaves inconsistent state with no clean way out.
This is the problem distributed transactions are designed to solve. And the SAGA pattern is one of the more practical approaches to solving it.
What is the SAGA pattern?
A SAGA breaks a distributed operation into a sequence of local transactions — one per service. Each step publishes an event on success, triggering the next. If any step fails, compensating transactions are run in reverse to undo what was already committed.
Example 1 — no seats available on the Air India leg

Example 2 — no seats available on the IndiGo leg

Important point to keep in mind: Each step is a local transaction. This is extremely important — otherwise the larger SAGA will not be transactional at all.
Outbox pattern vs SAGA
Before reaching for a SAGA, ask whether you need one at all.
The outbox pattern handles the simpler case: one primary service, one downstream service. The upstream service writes its main record and an outbox event in a single local transaction. A relay delivers the event downstream. There is exactly one point of failure — the initial write. If it succeeds, the downstream will eventually catch up.
The airline booking can't use this model. There is no single primary write — all three steps are peers, each owning their own data. Any of the three can fail after the others have already committed.
Use the outbox pattern if there is only 1 transaction which can have non-retryable error for example validation error. All the other transactions will eventually succeed on retry. Reach for a SAGA only when there are multiple independent transactions which will always succeed on first show or on retry.
Constraints a correct SAGA must satisfy
SAGAs trade away the clean guarantees of a database transaction. Two constraints must be enforced explicitly to compensate.
Semantic locks for isolation
A database transaction is invisible to others until it commits. A SAGA in progress is not — its intermediate state is visible for as long as the workflow takes. Without a guard, another process can observe and act on partial state.
In the airline booking, once the IndiGo seat is reserved but before payment is captured, a seat availability query could see an inconsistently low count. A fraud check could see a payment mid-flight and not know what to do with it.
The fix is a semantic lock: mark the seats on AirIndia and indigo as BLOCKED at the start and hold it there until the SAGA either confirms or fails. Other processes treat BLOCKED seats as off-limits.
 This is enforced by application code, not the database. Compensating transactions must release the lock in every failure path — a missed release leaves records stuck in
This is enforced by application code, not the database. Compensating transactions must release the lock in every failure path — a missed release leaves records stuck in PENDING permanently.
Reliable execution
All the steps in a SAGA must execute to completion. Let's say we do a naive implementation by writing all the steps in a single service. Such an approach will not ensure transactionality — if the server crashes while booking the IndiGo ticket, we end up with seats booked but payment not processed. We need to make sure all steps resume after the server comes back up. This property is called reliable execution.
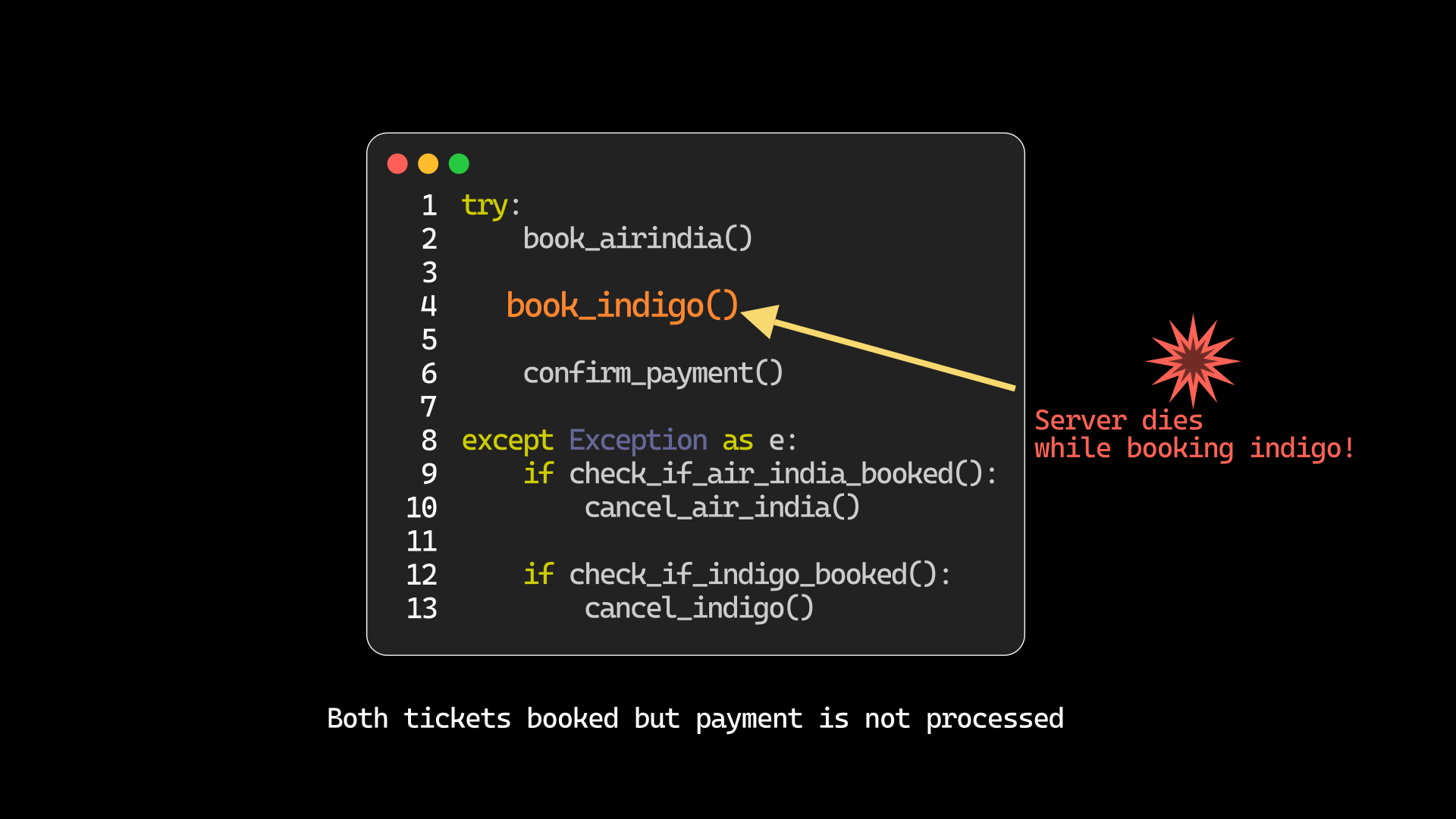
Reliable execution can be implemented with Kafka or RabbitMQ. If each step is published as a message to a broker, it is persisted to storage. When the server comes back up, the message is picked up and the step is executed again.
One subtlety: publishing the Kafka message and committing the local transaction must be atomic. If the server crashes between the two, you either lose the event or publish it without the local state being committed. The outbox pattern solves this — write the event to a local outbox table in the same transaction, then relay it to Kafka. This ensures the two are always in sync.
At-least-once execution and idempotency
All message brokers ensure at-least-once delivery. This means Kafka/RabbitMQ guarantees that all messages will be delivered at least once, but may be delivered more than once in some edge cases A consumer crash mid-processing or a rebalance can cause a re-delivery.
To work around this every step must be idempotent. The standard approach is a processed-events table — each step records the SAGA ID before acting, and skips the operation if it has already seen that ID. The check and the recording the SAGA ID must be in the same local transaction. If they're separate, it may break transactionality in some edge cases.
Ordering Saga steps: the point of no return
Some steps cannot be compensated. Issuing a ticket number to a government system, sending a booking confirmation email — once these happen, they cannot be undone.
This is not a constraint to enforce but a property to exploit when ordering steps. Reversible steps come first. Irreversible steps come last. By the time the Saga reaches an irreversible step, all prior steps have committed — the only direction is forward, and that step is expected to eventually succeed.
Steps after the point of no return have no compensation path. The system retries them until they succeed.

Implementing Saga with Kafka
Kafka's at-least-once delivery is a natural fit for SAGA execution — no step is silently skipped, and a consumer that crashes mid-processing resumes from where it left off. Each step is a Kafka consumer that reads from an input topic, executes a local transaction, and publishes to an output topic. The offset is committed only after the local transaction commits — this ordering is what makes the step reliable.
for message in consumer:
saga_id = message.value["saga_id"]
with db.transaction():
# Skip if already processed (idempotency)
if db.execute("SELECT 1 FROM processed_events WHERE saga_id = %s", saga_id):
consumer.commit()
continue
# Execute local state change
db.execute("UPDATE seats SET status = 'CONFIRMED' WHERE saga_id = %s", saga_id)
# Record as processed — same transaction as the state change
db.execute("INSERT INTO processed_events (saga_id) VALUES (%s)", saga_id)
# Write next event to outbox — same transaction, relayed to Kafka by a separate process
db.execute("INSERT INTO outbox (topic, payload) VALUES (%s, %s)",
"payment.requested", json.dumps(message.value))
# Offset committed only after transaction commits
consumer.commit()
Each service records processed SAGA IDs in its own local table — checked and written in the same transaction as the state change. Kafka topic retention for compensation topics must outlive the longest possible SAGA execution; a compensation event that arrives after its topic expires is unprocessable, and that's the one failure mode that breaks consistency silently.
Hands-on challenge
Reading about SAGAs is not the same as wiring one up and watching it fail. The guarantees only become intuitive once you've seen what breaks when they're missing.
The challenge is built around a simplified airline booking flow — the same 3-step sequence from this post, running against a real Kafka cluster with a chaos layer that injects failures at random steps. Your job is to implement the consumer loop and compensation logic such that no completed booking is left in an inconsistent state, regardless of where the failure lands.
A SAGA is only as correct as its worst failure path. The challenge is designed to find yours.
